基于在网计算的分布式系统加速方法
基本信息
- 背景
- 在网计算是后摩尔时代提升算力的有效方法
- 分布式系统扩展面临功耗墙、存储墙,搬动数据开销达到整体70%
- 定义
- 在网计算是将标准应用卸载到网络设备上的计算模式
- In-Network Computing is the offloading of standard applications to run within network devices
- 意义
- 压缩网络流量,低时延通信,高速计算
- 适用于分布式应用加速,如:分布式大模型训练、分布式数据分析、分布式存储系统
- 与传统方案对比
- 传统方案的现状
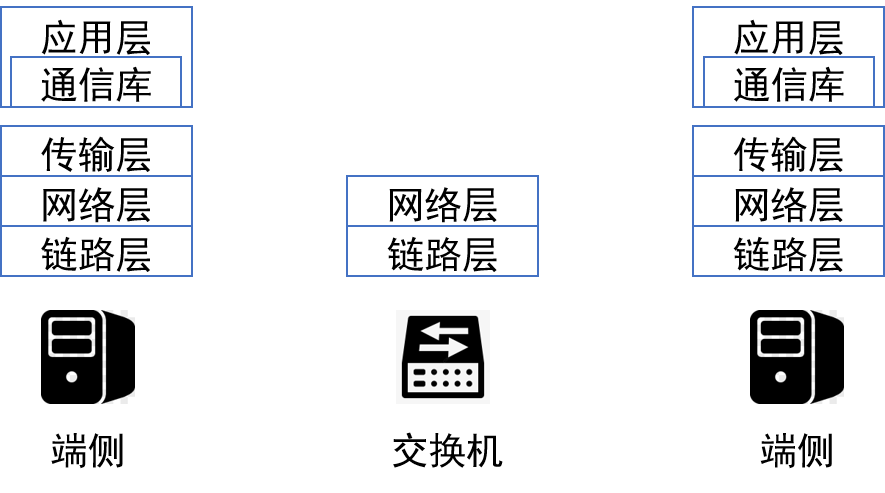
- 分层结构各层独立,各自优化,形成生态,性能无法达到最优
- 应用异构性较大,形成各自的通信模式
- 在网计算的发展空间
- 大型集群计算成为新趋势,集群归一方所有,分层设计的前提不再具备
- 各层具备可编程性、可定制性
- 集群建设成本高昂,提升效率意义重大
- 传统方案的现状
- 发展路线
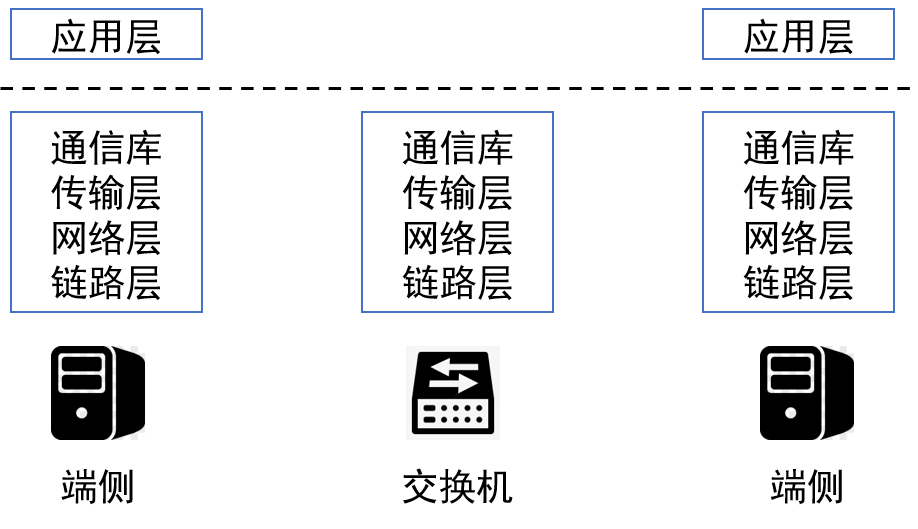
- 打通二至五层,各应用领域独立设计;在各个应用领域验证并取得收益
- 领域间逐步整合,重新设计通信库标准;使应用开发者迁移到新的开发模式
- 功能下沉,更新设备,进一步提升性能;促进大规模商业化生产
技术方案
加速分布式机器学习 【前置信息】
- 背景
- 机器学习:自然语言处理、计算机视觉、智能运维
- 分布式机器学习:增长的数据集、增长的模型、场景要求(联邦学习)
- 机器学习训练算法
- 重复迭代计算梯度,更新模型直至收敛
- 分布式训练:每个worker计算梯度 –> 所有梯度聚合并返回给worker –> 更新模型
- 分布式训练参数服务器(Parameter Server, PS)
- 假设:N个worker,梯度大小为M
- 通信量 worker: M PS: N * M 【问题与目标】
- 问题
- PS链路成为瓶颈
- 目标
- 主要目标:使用在网计算加速分布式训练
- 其他目标:兼容性、多任务、跨机柜
【方案1】交换机取代PS (NetReduce)
- 目标
- 主要目标: 使用在网计算加速分布式训练
- 其他目标:与RDMA兼容
- PS的类型及工作方式
- 服务器
- 每个worker把数据发送到PS
- PS把数据求和
- PS将结果广播给worker
- 交换机
- 交换机能流式处理报文,但是不能缓存大块数据
- 交换机没有四层协议保证数据块完整
- 服务器
- 体系结构
- Worker:梯度消息被组织为一个报文序列,维护一个滑动窗口发送报文,假设窗口最大值为W
- 交换机:内存组织为一个聚合器数组,大小为N
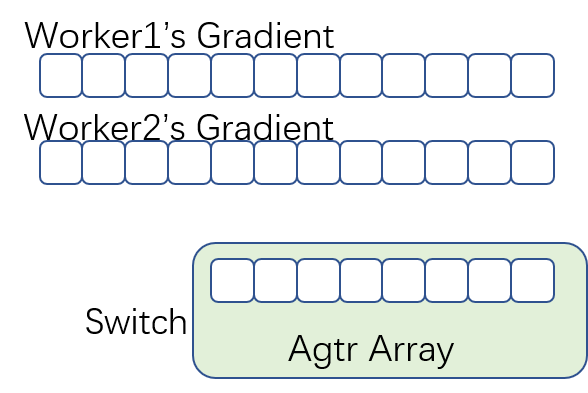
- 工作流程
- Worker发送梯度报文,交换机通过聚合器数组实时聚合(agtr.idx = PSN%N)
- 一个聚合器中的聚合完成(通过bitmap判断),将结果组播给workers
- worker的滑动窗口继续滑动,发送新的报文
- 性能结果
- NetReduce提升训练效率,获得在网聚合和RDMA双重性能增益
- 训练AlexNet比Ring AllReduce快45%
- 小结
- 可以用交换机替换PS
- 可以做到对传输层透明,与RDMA集成
- 内存管理:交换机内存为端侧窗口两倍
【方案2】 聚合传输协议设计ATP
- 背景
- 多租户:多任务共享基础设施
- 多机柜:BERT-Large训练跨多机柜
- 目标
- 主要目标:使用在网计算加速分布式训练
- 次要目标:支持多租户任务、支持跨机柜部署
- 内存分配类型
- 静态交换机内存分配
- 划分交换机内存为隔离的区域,分配给多任务
- 交换机内存低效率、集成复杂
- 动态交换机内存分配
- 交换机内存为一个聚合器资源池,对于每个任务的报文采用先到先服务
- 去中心化聚合器寻址
- Agtr.idx = Hash(JobID, PSN)
- 静态交换机内存分配
- 体系结构
- 保留PS,寻址可能失败,需要回退机制(Fallback),交换机难以正确处理重传报文
- 聚合器,记录JobID、Seq,检测冲突,释放需要由ACK完成
- 工作流程
- worker端维护滑动窗口,发送梯度报文
- 梯度报文抵达交换机,进行寻址
- PS接到聚合结果或者透传报文,完成聚合,返回ACK
- ACK抵达交换机,释放聚合器,推动滑动窗口
- 性能结果
- 通信瓶颈任务吞吐量提升显著,多任务竞争下资源利用率更高
- 小结
- 统计复用交换机,利用率更高
- 正确性机制更复杂
【方案1与方案2对比】
- 组成
- 方案1:交换机
- 方案2:交换机+PS
- 寻址机制
- 方案1:冲突避免(模运算)
- 方案2:冲突探测(Hash)
- 内存使用
- 方案1:2倍窗口
- 方案2:1倍窗口
- 内存分配
- 方案1:隔离
- 方案2:共享
- 适用范围
- 方案1:单任务隔离
- 方案2:多任务共享
- 优势
- 方案1:可预测性能,不需PS
- 方案2:高资源利用率
- 背景
分布式机器学习任务管理 【资源管理】
- 应用和系统目标
- 高性能,资源利用率,公平性
- 策略
- 循环(round robin),多级反馈队列(multi-level feedback queue)
【调度策略】
- 最早截止时间优先(Earliest Deadline First)
- 优先将交换机内存分配给截止时间早的任务
- 剩余内存共享给BE任务和暂时无法满足的MD任务
- $$ \begin{array}{c}\text{Time}_{\text{job}} = \text{Epochs} \times \left( \text{Time}_{\text{comp}} + \dfrac{\text{Size}_{\text{model}}}{\text{Throughput}} \right) \\\\\text{Memory}_{\text{switch}} = \text{Throughput} \times \text{RTT}\end{array} $$
【内存管理】
- 交换机内存管理器
- 北向接口:内存分配
- 南向接口:向终端发送内存区域(offset, size),向交换机发送规则
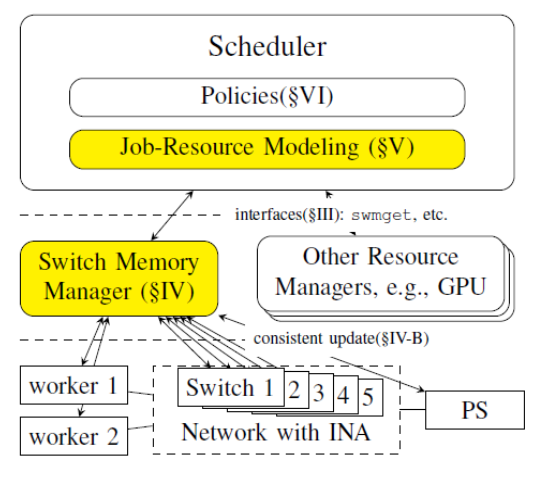
- 寻址模式
- agtr.idx ← Hash(PSN, JobID)%Size + Offset
- 端侧计算地址,并封装在报文头部
【性能结果】
- 交换机内存管理可以有效降低平均任务完成时间,提高服务满足率
- 应用和系统目标
加速大数据分析系统
【挑战】
- 大数据存在数据流聚合
- 大数据系统中的 ReduceByKey()
- 数据库系统中的 sum 、 count 等
- 大数据系统中的聚合为异步聚合
- 同步聚合(机器学习)值流(value stream)
- 键相同
- 键线性排列,可预知
- 键次数有界
- 异步聚合(大数据)键值流(key-value stream)
- 不同流中键不同
- 键无序,不可预知
- 键次数没有界
- 同步聚合(机器学习)值流(value stream)
【目标】
- 目标
- 适配不同的应用
- 提升系统效率
- 有正确性保证
【创新设计】
- 提升系统有效吞吐率
- 多元组报文
- 二维聚合器数组(Aggregator Array,AA)
- 端侧元组顺序重构
- 将键的空间划分为互不重叠的子空间
- Hash(Flow ID) –>子空间
- 报文有多个槽位(slot)
- 提升155倍处理速度
- 可靠性和正确性
- 基于seen状态位避免重复计算
- 提升内存使用效率
- 双副本AA动态切换,优先处理高频键
【性能结果】
- 词频统计任务耗时比Spark(56核)减少50%以上,CPU利用率显著降低
- 大数据存在数据流聚合
通信库设计 【背景】
- 在网计算对于应用(框架)开发者并不友好,学习曲线陡峭,难以集成到分布式系统中
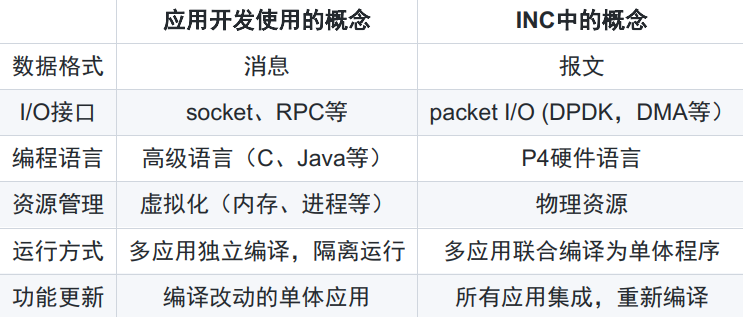
【目标】
- 实现对开发者友好的通信计算库
【实现方法】
- INC应用分类:同步聚合、异步聚合、键值读写、共识协议
- 统一各分类中的数据格式
- 统一交换机中的原语
- 统一应用编程接口
- 系统集成
【性能结果】
- 节约代码行数
- 对比其他INC方案性能接近,对比端侧系统吞吐量更高、时延更低
总结
- 在网计算是有效提升分布式应用效率的一种手段
- 在网计算应用场景广泛,也是一个很大的研究空间
基于在网计算的分布式系统加速方法
http://example.com/2025/06/29/基于在网计算的分布式系统加速方法/