基于网内聚合的分布式机器学习加速策略研究
摘要
- 研究背景
- 大规模神经网络训练需求激增,单机训练效率低,而PS-Worker、AllReduce存在显著缺陷
- PS-Worker:参数服务器带宽瓶颈限制规模扩展
- AllReduce:通信延迟随节点数线性增长
- 网内聚合( In-Network Aggregation)
成为了加速分布式机器学习训练的新方向
- 通过可编程交换机将梯度聚合卸载到网络层,减少主机计算压力与网络流量
- 受限于交换机内存与计算能力
- 大规模神经网络训练需求激增,单机训练效率低,而PS-Worker、AllReduce存在显著缺陷
- 核心问题
- 问题1:
- 多任务争抢可编程交换机有限的内存资源,而导致网内聚合速度减慢和交换机内存利用率降低
- 问题2
- 网内聚合扩展规模受限于可编程交换机有限的计算能力,大规模分布式训练中部署难度和成本高, 以及现有网内聚合扩展策略没有充分利用机内高带宽资源
- 问题1:
- 解决方案
- 问题1:RA-INA混合同步算法
- 动态共享交换机内存,梯度分组后优先执行Ring-AllReduce
- 数据包到达交换机时批量抢占聚合器,成功则切换网内聚合
- 问题2:CINA链式扩展策略
- 将 ToR(Top of Rack)交换机替换为可编程交换机,在 ToR 层形成一条网内聚合的链式流水线
- 利用机内高带宽,在机内进行 Ring-Reduce 将梯度聚合到机内主节点上,协同流水线进行机间的网内聚合
- 问题1:RA-INA混合同步算法
- 关键词
- 分布式机器学习
- 可编程交换机
- 网内聚合
- 多任务
- 大规模训练
第一章 绪论
- 研究背景及意义
- 核心问题
- 大规模神经网络训练(如ChatGPT)需求激增,单机训练耗时过长(如1024块A100训练34天),分布式训练成关键技术。
- 通信瓶颈
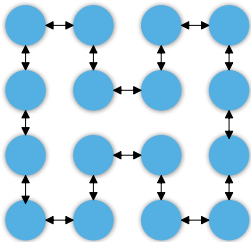
- PS-Worker
- 参数服务器(PS)节点多对一通信导致带宽瓶颈

- AllReduce
- 通信延迟随节点数线性增长,长环结构受限于最低带宽链路
- PS-Worker
- 网内聚合价值
- 通过可编程交换机卸载梯度聚合,减少网络流量与通信跳数,但受限于交换机内存与计算能力
- 核心问题
- 研究现状
- 中心化并行训练(PS-Worker)
- 工作流程
- 作为中心化的 PS 将在本地维护一个全局模型, 负责更新 Worker 上的本地模型。 在每次迭代训练中,训练数据集会被分割并分配给每个 Worker 进行本地训练,完成训练后计算梯度值并将其推送给 PS。 PS 收到来自各个 Worker 的梯度后,使用随机梯度下降法或其他优化算法更新全局模型。随后 Worker 会从 PS 拉取最新的模型以便进入下一次迭代训练。
- 演进历程
- 第一代
- 基于Memcached的分布式参数存储
- 第二代
- DistBelief
- 第三代
- PS-Lite通用架构
- 第一代
- 优化方案
- 数据/模型并行
- SINGA
- CNTK
- 重叠计算/通信
- WFBP
- BytePS
- 弹性参数服务器
- EPS
- Pathways
- 数据/模型并行
- 工作流程
- 去中心化并行训练(AllReduce)
- 工作流程
- 不同于参数服务器模式需要 PS 和Worker 两类工作节点,在 AllReduce 模式中只需要 Worker 节点, 模型参数或梯度只在 Worker 之间传输,每个 Worker 都是平等的
- 将所有 Worker连接成一个逻辑环,每个 Worker 把本地计算得到的梯度划分成 N 份并依次把自己的梯度同步给下一个邻居Worker,总共经过 2*(N-1)轮同步, 才能够完成所有 Worker 的梯度更新
- 优化方案
- 分层同步
- Hierarchical-AllReduce
- 2D-Torus AllReduce
- HiPS
- 异构问题
- BlueConnect
- Blink
- FlexReduce
- DS-Sync
- 分层同步
- 工作流程
- 网内聚合技术
- 基于可编程网络设备(如可编程交换机、 FPGA 或智能网卡等) 的计算能力加速各种聚合应用
- 中心化并行训练(PS-Worker)
- 研究内容
- 基于 Ring-AllReduce 与网内聚合的混合同步算法
- 大规模分布式机器学习训练的网内聚合CINA链式扩展策略
第二章 相关技术概述
- 分布式并行训练策略
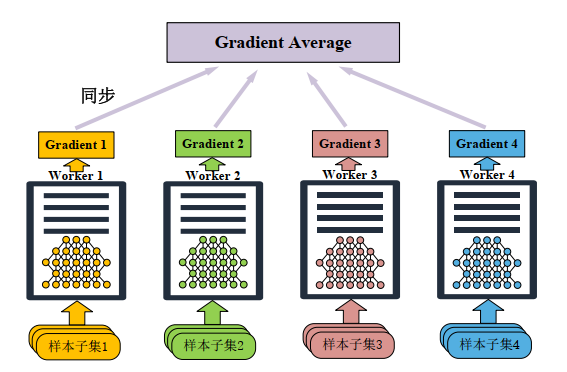
- 数据并行训练
- 核心原理
- 数据集切分到不同计算节点,每个节点持有完整模型副本进行本地训练
- 同步机制
- PS-Worker模式:Worker推送梯度至PS,PS聚合后广播更新(易带宽瓶颈)
- AllReduce模式:节点间直接同步梯度(无中心节点)
- 挑战
- 通信开销随节点数增长,可能引发掉队者问题
- 核心原理
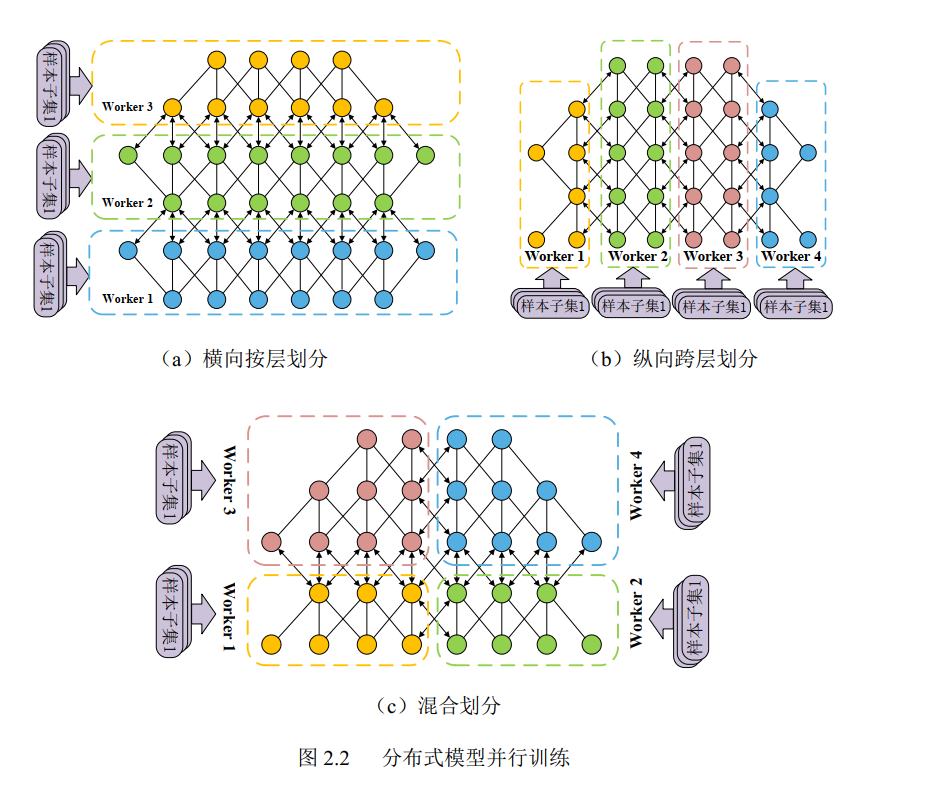
- 模型并行训练
- 核心原理
- 模型按层/神经元切分到不同节点
- 划分策略
- 横向按层划分
- 节点负责特定网络层(层数多时适用)
- 纵向跨层划分
- 单层参数矩阵分块(神经元多时适用)
- 混合划分
- 结合横向与纵向策略
- 横向按层划分
- 核心原理
- 数据并行训练
- 网内聚合
- 可编程交换机
- 核心架构
- RMT(可重构匹配表)模型支撑数据包处理
- 关键部件
- 解析器:提取/修改数据包头部字段
- 匹配部件:执行流表规则(匹配+动作集)
- 编程语言:P4定义数据包处理流程
- 挑战限制
- 聚合流量可能高达数十个 Gb 甚至 Tb,远超 RMT 交换机的内存容量
- SRAM/TCAM内存仅数十MB,需精细管理
- 核心架构
- 网内聚合的应用
- 分布式机器学习
- 减少网络流量与主机计算负担
- 类MapReduce应用
- 使用网内聚合在交换机侧完成部分数据的规约任务, 在 Reduce 阶段减少发送给 Reducer 节点的数据, 降低 Incast 现象出现的概率
- 分布式存储修复
- 减少数据传输量、提高修复效率、降低存储节点负载
- 分布式机器学习
- 可编程交换机
- 集合通信及分布式训练框架
- 集合通信
- Broadcast
- 单节点数据分发至所有节点
- Gather/AllGather
- 收集所有节点数据
- Reduce/AllReduce
- 跨节点数据聚合(求和/最大值等)
- Scatter/Reduce-Scatter
- 数据分块分发与局部聚合
- Broadcast
- 分布式训练框架
- TensorFlow
- 数据流图架构,支持gRPC通信
- 高级API与低级API灵活适配
- PyTorch
- 动态计算图,支持GLOO/MPI/NCCL通信后端
- MXNet
- 跨语言支持,轻量级分布式训练
- TensorFlow
- 集合通信
第三章 基于 Ring-AllReduce 与网内聚合的混合同步算法设计
- 问题分析
- Ring-AllReduce 同步算法
- 算法逻辑
- 所有计算节点 在逻辑拓扑上形成一个环,计算节点反向传播结束得到梯度后,会将梯度均匀切分成 n 份。每个节点错开将其中一份梯度发送给右邻居,并接收左邻居的一份梯度与本地梯度进行聚合。然后每个节点再将上一步聚合好的一份梯度继续发送给右邻居,重复上一步的操作。在进行 n-1步后,每个节点都将得到一份聚合了所有节点梯度的结果。 之后每个节点继续将聚合结果发送给右邻居,同时接收左邻居的聚合结果并覆盖本地位置的梯度。然后每个节点再将上一步接收的聚合结果继续发送给右邻居,重复上一步的操作。在进行 n-1 步后,每个节点都将得到整份聚合了所有节点梯度的结果
- 优势
- 通信量固定(不超过2倍模型大小)
- 缺陷
- 通信延迟随节点数线性增长
- 算法逻辑
- 网内聚合算法
- 算法逻辑
- 计算节点将梯度打包发送给可编程交换机,可编程交换机接收到梯度数据包之后寻找到对应的聚合器进行聚合。当聚合器识别到聚合完所有计算节点的梯度数据包之后,将对聚合结果进行打包并广播给所有计算节点
- 优势
- 将主机侧的聚合操作卸载到交换机侧,在网络中减少聚合流量,降低通信开销
- 缺陷
- 多任务争抢交换机内存导致效率下降
- 内存分配机制对比
- 静态固定内存分配
- 每个任务在可编程交换机中平均分配一块内存,任务之间相互隔离,互不影响
- 内存利用率低
- 动态共享内存分配
- 内存由多个任务共享,每个任务的梯度数据包按照先到先服务的机制占用聚合器。此外 ESA 还能通过优先级机制抢占已被占用的聚合器
- 需要PS节点容错,有可能将回退成 PS-Worker 的训练模式
- 在多训练任务的场景下采用动态共享内存分配模式更能充分发挥网内聚合的性能
- 静态固定内存分配
- 算法逻辑
- Ring-AllReduce 同步算法
- 混合同步算法设计(RA-INA)
- 整体概述
- 主要流程
- 初始化工作, 在同步开始时,可编程交换机将内存划分成大小相同的聚合器, 每个聚合器负责一组梯度的聚合任务。计算节点将梯度切分成大小与聚合器内存相同的梯度块,并将梯度块分组, 然后对按组将梯度块打包成梯度数据包发送到可编程交换机中进行网内聚合
- 当某个节点的梯度数据包在可编程交换机中寻找到连续的 n 个聚合器时,该梯度数据包将批量占领这 n 个聚合器,并将梯度缓存在对应的聚合器中
- 部分梯度块将转而执行网内聚合算法,并在完成所有计算节点的梯度聚合工作之后,可编程交换机会将聚合结果广播给每个计算节点
- 若没有在可编程交换机中寻找到满足要求的聚合器组,则该梯度数据包所在的梯度组将继续执行算法的下一步
- 如果之后 算法执行到 n-1 步之后,即AllGather 操作时, 该梯度组将不再尝试寻找空闲聚合器, 继续完成 AllGather 操作
- 核心理念
- 动态混合执行
- 梯度同步过程在 Ring-AllReduce 与 网内聚合间动态切换,通过交换机内存占用状态决策执行路径
- 批量抢占机制
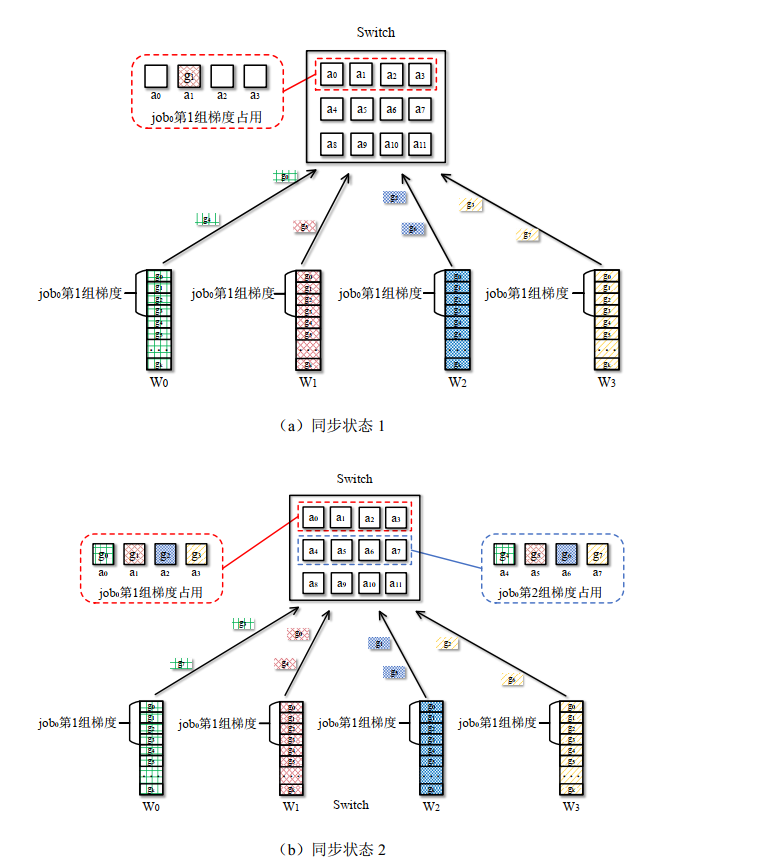
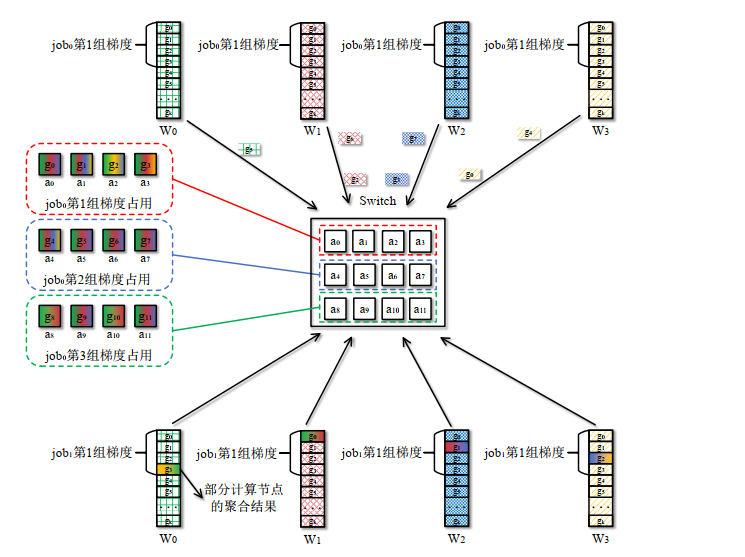
- 梯度数据包到达交换机时,尝试批量占领与计算节点数相等的聚合器组(非单个抢占),成功则切换网内聚合
- 动态混合执行
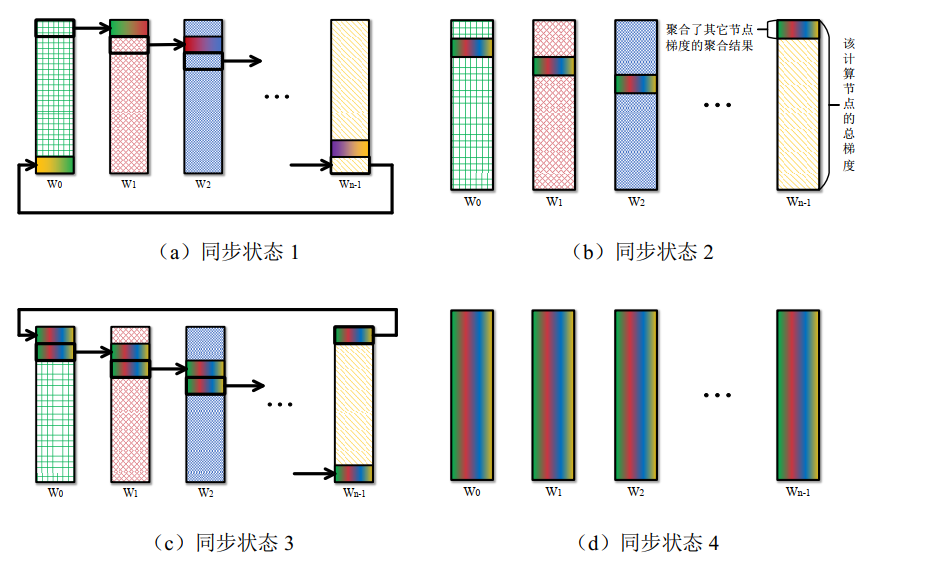
- 过程示例
- 单任务
- 多任务
- 单任务
- 主要流程
- 整体概述
- 主机侧逻辑设计
- 数据预处理
- 梯度切分
- 按 64个梯度元素/块切分
- n个梯度块为一组(n=节点数),形成逻辑分组
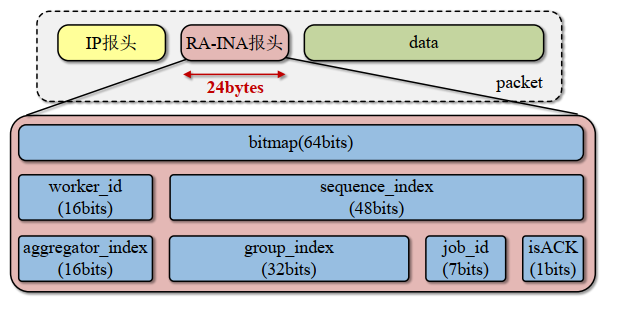
- 数据包格式
- 梯度切分
- 通信控制逻辑
- 滑动窗口
- 每组梯度独立维护状态机,完成一组后滑动至下一组
- 浮点处理
- 梯度缩放为32位整数传输,交换机聚合后主机侧还原为浮点数
- ACK响应逻辑
- 接收聚合结果后返回ACK,触发交换机释放聚合器
- 超时未收到ACK则重传数据包
- 滑动窗口
- 数据预处理
- 交换机侧逻辑设计
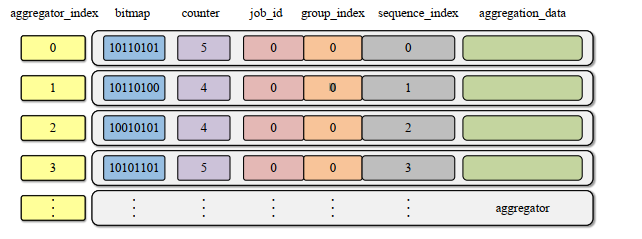
- 聚合器结构设计
- 处理流程
- 聚合器匹配
- 根据包头
job_id和group_index定位聚合器组 - 若未占用,遍历寻找连续n个空闲聚合器
- 根据包头
- 数据聚合
- 校验
bitmap防止重复聚合 - 整型梯度累加到
data区,更新bitmap和counter
- 校验
- 广播触发
- 当
counter == n且bitmap全1时,广播聚合结果
- 当
- 聚合器匹配
- 聚合器结构设计
- 可靠性设计
- 丢包处理机制
- 主机→交换机丢包
- 2MSL未收到ACK
- 重传梯度数据包
- 交换机→主机丢包
- 2MSL未收到结果ACK
- 交换机重发聚合结果
- ACK丢包
- 重复数据包触发bitmap校验
- 丢弃重复包,补发ACK
- 主机→交换机丢包
- 丢包处理机制
- 实验分析
- 网内聚合性能影响因素分析
- 内存利用率高
- 任务数影响小
- 内存不足性能衰减小
- 单任务时的训练吞吐量对比
- 比Ring-AllReduce 吞吐量提升57%
- 比PS-Worker 加速2.0倍
- 多任务时的平均任务完成时间对比
- RA-INA比SwitchML JCT降低25.4%
- RA-INA比Ring-AllReduce JCT降低18.1%
- 网内聚合性能影响因素分析
第四章 大规模分布式训练的网内聚合扩展策略设计
- 问题分析
- HINA分层网内聚合扩展策略
- 同步流程
- 首先所有服务器中的计算节点将梯度数据包向上发送到各自所在的 ToR 交换机进行第一次网内聚合。 之后 ToR 交换机继续向上将聚合好的梯度数据包发送给 ToR 交换机所连接的 AGG 交换机, 进行第二次网内聚合。 然后 AGG 交换机仍然将聚合好的梯度数据包向上发送给所连接的 Core交换机进行最后一次网内聚合。 最后作为根节点的 Core 交换机将得到所有计算节点梯度数据包的聚合结果, 并原路进行组播。 在每一层中, 该层的交换机都将进一步组播梯度数据包,最终到达每个计算节点, 完成本次梯度同步
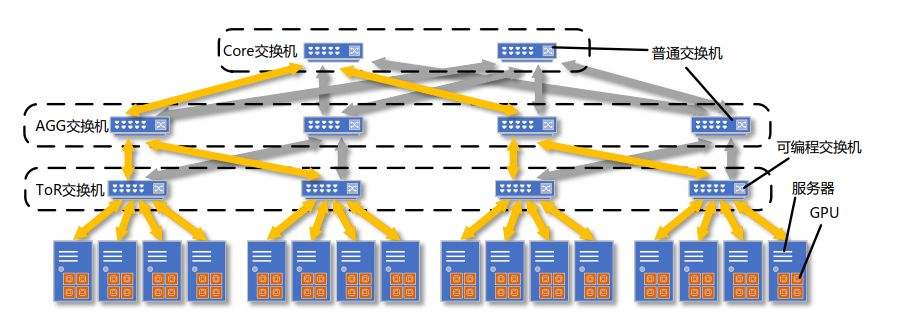
- 缺陷
- 需替换多层级交换机(ToR+AGG+Core),部署成本高
- 同步流程
- MTINA多树网内聚合扩展策略
- 同步流程
- MTINA 将根据参与训练任务的计算节点分布情况,以 Core 交换机为根节点初始化生成多棵聚合树。 与 HINA 中生成的聚合树相同, MTINA 中每棵聚合树的叶子节点均为计算节点,非叶子节点均为具有计算功能的可编程交换机
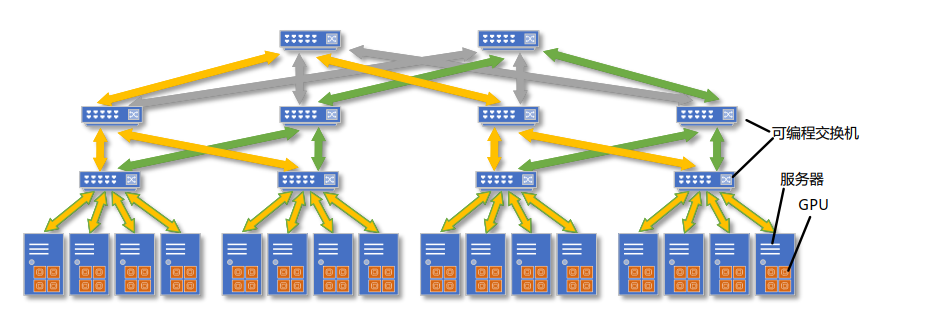
- 缺陷
- 构建多聚合树需全网可编程交换机,成本激增
- 同步流程
- HINA分层网内聚合扩展策略
- 链式网内聚合扩展策略设计
- 整体结构(以Spine Leaf 网络架构为例)
- 网络拓扑
- Spine-Leaf架构,仅替换Leaf层为可编程交换机
- 四阶段流水线:
- 机内Ring-Reduce
- GPU间高带宽聚合梯度至Master Node
- 机架内INA
- ToR交换机聚合本机架Master Node数据
- 机架间链式聚合
- ToR交换机形成流水线,跨机架迭代聚合
- 结果组播
- 最终聚合结果广播回Master Node
- 机内Ring-Reduce
- 网络拓扑
- 机内聚合策略
- 主节点选择
- 规则
- 每台服务器固定选择末位GPU为Master Node
- 作用
- 作为机内聚合结果缓存点与机间通信代理。
- 规则
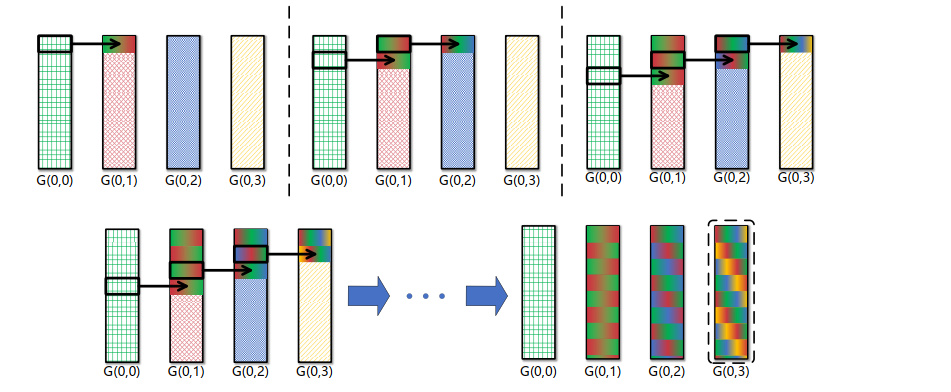
- Ring-Reduce流水线
- 执行流程
- 梯度切分
- 每GPU梯度分k块
- Reduce-Scatter
- G(i, 0) → G(i, 1)发送块0,同时接收G(i, 3) → G(i, 0)块3
- G(i, 1) → G(i, 2)发送块1,同时接收G(i, 0) → G(i, 1)块0
- …
- 聚合终点
- 经(n+k-2)步,所有梯度块聚合至G(i, 3)
- 梯度切分
- 执行流程
- 延迟公式
- $T_{机内RR} = \frac{(n+k-2)K}{kB_{dtd}} + (n+k-2)\alpha_{dtd}$(n=GPU数,K=梯度大小n=GPU数, K=梯度大小n=GPU数,K=梯度大小)
- 主节点选择
- 机架内聚合策略
- ToR交换机
- 核心功能
- 聚合本机架内所有Master Node梯度
- 生成机架级聚合结果
- 核心功能
- 通信重叠优化
- Master Node在接收第一份聚合梯度后立即发送至ToR交换机
- 覆盖机内剩余通信时间
- $T_{重叠} \leq T_{机内RR} - \left(n-1)\times( \frac{K}{kB_{htl}} + \alpha_{htl} \right)$
- ToR交换机
- 机架间聚合策略
- 链式聚合原理
- Leaf交换机按Pod编号串联
- 工作流程
- LS0:发送本地聚合结果g2t(0)至LS1
- LS1:计算g3t(1) = g2t(1) + g2t(0),发送至LS2
- LS2:计算g3t(2) = g2t(2) + g3t(1),发送至LS3
- LS3:获得全局聚合结果g3t
- 通信重叠优化
- $T_{CINA}=T_{机内RR}-T_{重叠}+\frac{K}{B_{htl}}+\alpha_{htl}+(L-1)\times(\frac{K}{kB_{lts}})+\frac{K}{kB_{min}}+\alpha_{min}$
- 链式聚合原理
- 整体结构(以Spine Leaf 网络架构为例)
- 仿真分析
- 理论通信开销推导与对比
- Ring-AllReduce
- $T_{Ring}=2(N-1)\times(\frac{K}{NB_{min}}+\alpha_{min})$
- PS-Worker
- $T_{PS}=(k+1)\times(\frac{K}{kB_{min}})+2\alpha_{min}$
- HINA
- $T_{HINA}=T_{机内RR}-T_{重叠}+\frac{K}{B_{htl}}+\alpha_{htl}+2\times(\frac{K}{kB_{lts}}+\alpha_{lts})+\frac{K}{kB_{min}}+\alpha_{min}$
- MTINA
- $T_{MTINA}=(k+1)\times(S+1)\times(\frac{K}{kSB_{min}})+(S+1)\times\alpha_{min}$
- 优势对比
- CINA 只在服务器与上层交换机间存在多对一通信的压力,并不会一层一层的积累通信压力
- CINA 不需要像 HINA 和 MTINA 中将 Leaf 层和 Spine 层的交换机替换为可编程交换机,本设计只需要更换 Leaf 层的交换机,降低了部署难度和成本
- 三层网络最大支持节点数:CINA 14,338 > HINA 3,600
- 相同的节点规模下, CINA 的部署成本也比 HINA 和 MTINA 更有优势
- Ring-AllReduce
- 仿真平台搭建
- 平台架构设计
- 真实VGG19/ResNet50训练数据
- NS3构建可扩展Spine-Leaf网络。
- 实现五种对比算法
- 丢包率与聚合正确性监控
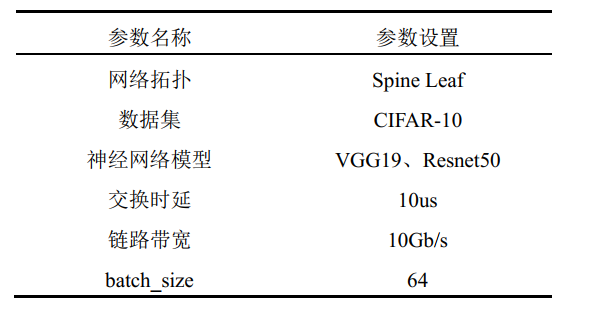
- 关键参数配置
- Trace激励源设计
- PyTorch Profiler + 自定义Hook
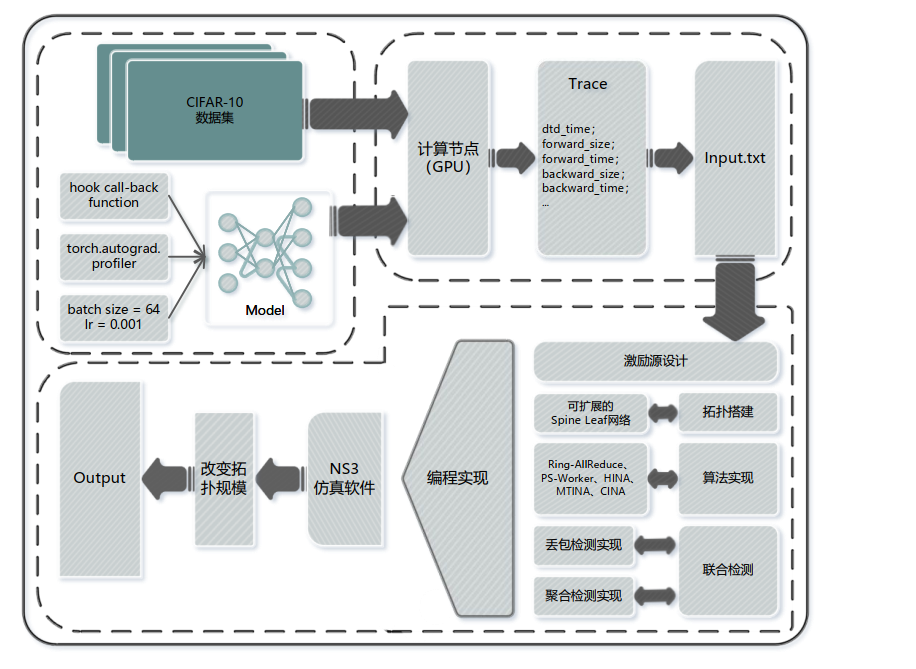
- 平台架构设计
- 仿真结果与分析
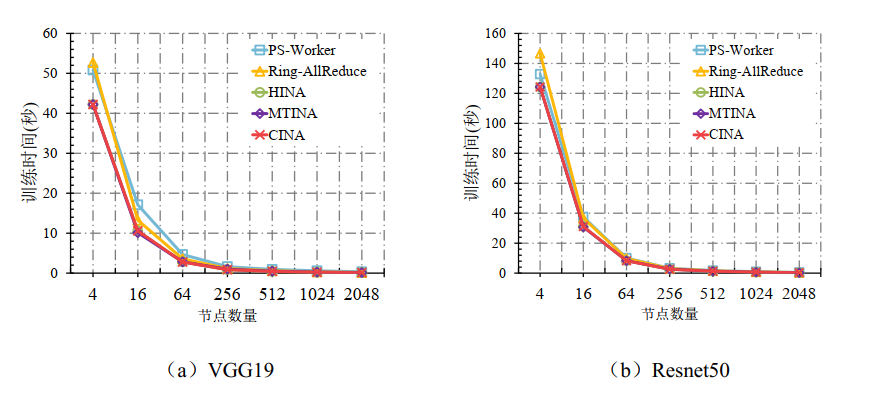
- 训练时间对比
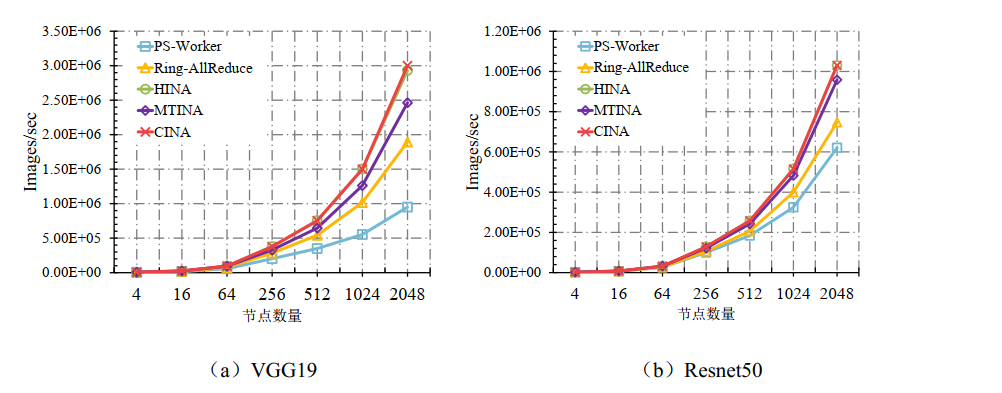
- 吞吐量对比
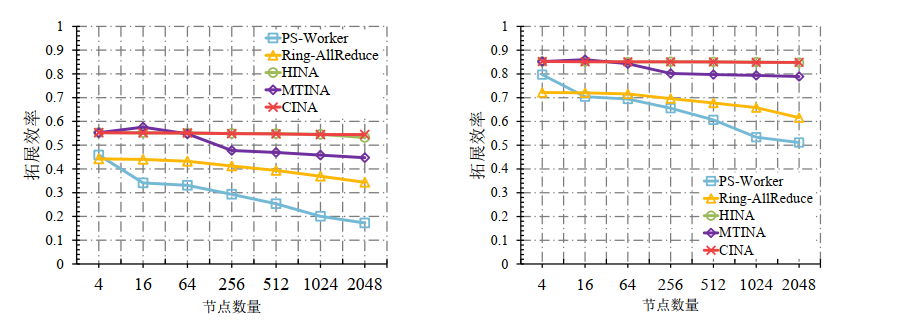
- 拓展效率对比
- 加速比对比
- 训练时间对比
- 理论通信开销推导与对比

第五章 总结与展望
- 总结
- RA-INA混合同步算法
- 解决痛点
- 多任务争抢交换机内存导致的效率下降
- 工作机制
- 动态共享内存
- 任务按梯度组抢占聚合器
- 混合执行逻辑
- Ring-AllReduce容错 + 网内聚合加速
- 动态共享内存
- 解决痛点
- CINA链式扩展策略
- 解决痛点
- 大规模分布式训练场景下网内聚合的扩展性问题
- 工作机制
- 多阶段流水线
- 机内Ring-Reduce → ToR层链式聚合
- 扁平化的聚合结构
- 多阶段流水线
- 解决痛点
- RA-INA混合同步算法
- 展望
- 同步算法对丢包容忍性
- 跨交换机甚至跨机架的实机实验平台
- 网内聚合应用在分布式模型并行训练场景,研究异步训练下的网内聚合算法设计
- 对于其他的可编程网络设备研究其网内聚合的分布式机器学习加速策略
基于网内聚合的分布式机器学习加速策略研究
http://example.com/2025/07/05/基于网内聚合的分布式机器学习加速策略研究/