ATP:多租户学习中的网络内聚合
Abstract 摘要
- 核心创新
- 提出ATP(Aggregation Transmission Protocol)服务
- 目标场景
- 多租户多机架集群中的分布式深度学习训练
- 关键技术
- 可编程交换机实现网络内梯度聚合
- decentralized, dynamic, best-effort aggregation中心化的、动态的、尽力而为的聚合资源分配
- 性能收益:
- 训练吞吐提升38%-66%
1. Introduction 引言
- 问题
- 通信瓶颈转移
- 专用硬件的最新进展已将分布式训练的性能瓶颈从计算转移到通信
- 在没有网络通信的情况下,VGG16训练速度可以提高4倍
- 多租户场景痛点
- 供多机架/多交换机集群中的多个 DT 租户利用这一普遍问题,尚未受到系统的关注。
- 实现这种服务需要一些机制,以便在多个租户之间共享有限的多交换机聚合资源
- 通信瓶颈转移
- ATP
- 梯度片段包
- ATP将每个DT作业的梯度分块成固定大小的片段
- 聚合器
- 将可编程交换机资源划分为相同大小的片段
- 去中心化的聚合器分配机制
- 通过在梯度片段数据包到达交换机时动态分配空闲聚合器,来支持多个作业在线速下进行聚合
- 专门对交换机逻辑和终端主机网络堆栈进行协同设计,以支持可靠性和有效的拥塞控制
- 浮点值量化机制
- 终端主机的内核旁路设计
- 有的协议栈不会被ATP的网络栈替换,非ATP应用程序可以继续使用现有的协议栈
- 梯度片段包
- 性能
- 多个作业的单机架DNN模型测试平台
- 当只有一半的所需聚合器可用时,性能仅下降5-10%
- 当交换机资源竞争激烈时,性能优于当前最先进的技术38%
- 典型的拓扑结构模拟
- ATP可减少66%的网络流量
- ATP的丢包恢复机制优于最先进的技术(SwitchML)34%
- 具有拥塞控制的ATP作业比没有拥塞控制的作业加速3倍
- 多个作业的单机架DNN模型测试平台
2. Background and Motivation 背景和动机
Preliminaries(预备知识)
- PS Architecture(PS架构)
- Worker本地计算梯度 → 跨网络传输至PS聚合 → 返回更新参数
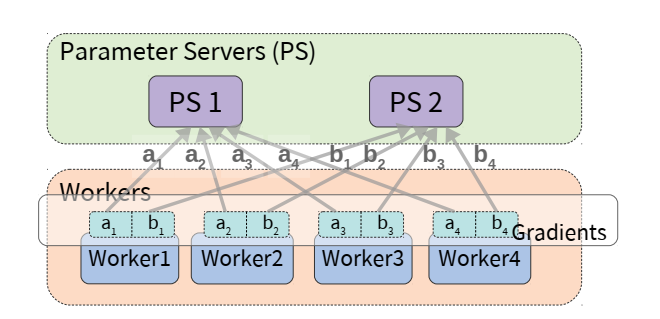
- Programmable Switch(可编程交换机)
- 无状态对象
- 元数据,保存每个数据包的瞬态状态,并且当该数据包被丢弃或转发时,交换机释放此对象
- 有状态对象
- 寄存器,只要交换机程序正在运行,就保持状态。可以在数据平面中读取和写入寄存器值,但对于每个数据包,只能访问一次,无论是读取、写入还是两者都进行
- 寄存器是一个值数组。在网络内聚合的上下文中,每个数据包都有一组梯度值,并且需要一组寄存器来聚合它们。我们将这组寄存器称为聚合器
- 限制
- 寄存器内存只能在交换机程序启动时分配。要更改内存分配,用户必须停止交换机,修改交换机程序并重新启动交换机程序
- 计算灵活性受到阶段数量、有效载荷解析能力以及每个阶段的时间预算的限制:只有独立的计算原语可以放置在同一阶段,并且在同一阶段访问的寄存器数量也受到限制
- 网络内计算和存储应用的数据包大小较小:SwitchML和NetCache的有效载荷大小为128B
- 无状态对象
- In-Network Aggregation(网络内聚合)
- 梯度可以被看作是一系列片段(每个片段都有一部分梯度值),所有梯度的聚合(梯度相加)就是每个片段的聚合。每个片段的网络内聚合都在特定的聚合器中完成
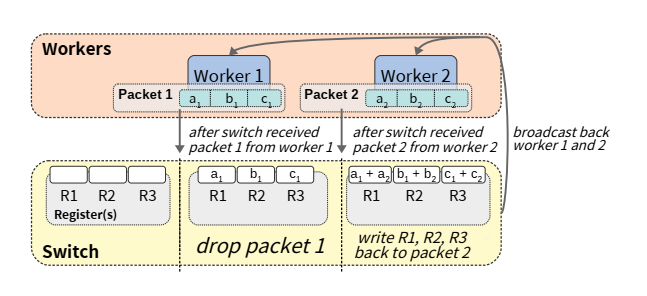
- PS Architecture(PS架构)
In-Network Aggregation as a Service(网络内聚合即服务)
- SwitchML的静态分配缺陷
- 资源低效
- 应用于多个DT作业时,SwitchML需要对交换机资源进行静态分区,其中每个作业被静态地分配到一个分区
- 固定分配聚合器导致任务间歇期(Off-Phase)资源闲置
- 可拓展性差
- SwitchML将每个DT作业的梯度聚合完全卸载到机架交换机。在交换机资源严重争用的情况下,DT作业必须等待交换机资源,从而导致从worker到PS的网络链路带宽利用不足
- 在网络拓扑的每一层启用聚合服务会使服务设计和网络操作复杂化
- 资源低效
- 协议层的挑战
- 端到端语义失效(Rethinking Reliability)
- 在聚合期间,一些数据包在网络内部被消耗。传统的基于终端主机的可靠性机制可能会将网络内数据包消耗误解为数据包丢失,从而导致不必要的重传,并且由于现有可靠性机制无法处理这些新型数据包事件,因此会导致不正确的梯度聚合
- 拥塞控制失真(Rethinking Congestion-Control)
- 多租户情况下,DT作业可用的网络资源(交换机聚合器和网络带宽)会发生波动
- 由于端到端语义被打破,无法使用依赖于RTT或丢包作为拥塞信号的传统拥塞控制算法
- 端到端语义失效(Rethinking Reliability)
- SwitchML的静态分配缺陷
3. Design 设计
ATP Overview(ATP概述)
- ATP VS TCP
- ATP针对其目标上下文重新设计了特定的传输特性,例如可靠性、拥塞控制和流量控制
- ATP不实现TCP的按序字节流和多路复用抽象,因为它们不适用于目标上下文
- 梯度分片处理
- 将梯度拆分为固定大小分片,通过
JobID和Sequence Number标识
- 将梯度拆分为固定大小分片,通过
- 动态聚合决策
- 分片通过哈希映射至交换机聚合器
- 资源不可用时直通PS端聚合
- 两级聚合层级
- 仅在工作节点机架(第一级)和PS机架(第二级)部署聚合,确保每个梯度分片数据包仅被聚合一次
- 检测处理丢包
- 使用基于超时的重传或来自PS的乱序参数ACK包。当一个包被重传时,它会设置重发标志
- 设置ECN标志,ECN拥塞信号经聚合多播至所有Worker
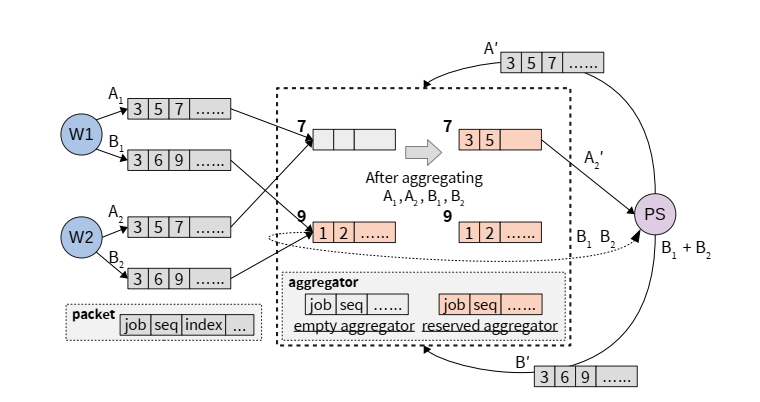
- ATP VS TCP
ATP Infrastructure Setup(ATP基础设施设置)
- 静态设置
- 交换机
- 每个可编程交换机安装一个分类器来识别ATP流量
- 分配一部分聚合器来聚合ATP流量
- 终端主机
- 安装一个ATP网络堆栈,该堆栈拦截来自DT作业的所有推送或拉取梯度调用
- 了解网络拓扑以及交换机上的聚合器总数,可以协调跨多个交换机的聚合
- 交换机
- 动态作业分配
- 标识分配
- 唯一
JobID+WorkerID
- 唯一
- 多播支持
- 使用IGMP来构建一个多播分发树,供PS将参数返回给worker
- 标识分配
- 静态设置
Data Structures(数据结构)
- 数据包格式
- bitmap0 / bitmap1节点聚合位图
- bitmap0:第一级交换机节点位图
- bitmap1:第二级交换机节点位图
- bitmap0:第一级交换机节点位图
- fanInDegree0 / fanInDegree聚合完成阈值
- fanInDegree0:第一级交换机需聚合的分片数
- fanInDegree1:第二级交换机需聚合的分片数
- resend重传标记
- 若值为1,此包为重传包,触发聚合器提前释放
- collision哈希冲突标记
- 若值为1,发生聚合器索引冲突,PS需触发动态重哈希
- ECN显式拥塞通知
- edgeSwitchIdentifier交换机层级标识
- 0:当前包由第一级交换机处理
- 1:当前包由第二级交换机处理
- 0:当前包由第一级交换机处理
- isAck包类型标识
- 0:梯度包(Worker → PS)
- 1:参数包(PS → Worker)
- 0:梯度包(Worker → PS)
- JobIDAndSequence分片唯一标识
- bitmap0 / bitmap1节点聚合位图
- 交换机寄存器
- bitmap位图记录哪些worker已被聚合
- counter记录已被聚合的workers数量
- ECN指示拥塞情况(只要存在ATP数据包的ECN字段为1,则置1)
- identify由job ID作业ID与sequence number序列号组成,唯一标识作业及片段
- timestamp时间戳的更新,发生在执行一次聚合操作时
- aggregator value存储聚合数据
- 数据包格式
Inter-rack Aggregation(机架间聚合)
- 原因
- 仅在worker的本地ToR交换机上进行聚合很简单,但是当worker位于不同的机架中时,会导致到PS的不必要的网络流量
- 可以在网络拓扑的更高层级进行聚合。然而,这种方法会大大增加协议的复杂性,因为系统必须处理网络内部的路由更改
- ATP部署位置
- ATP仅在ToR交换机中部署网络内聚合,要么在worker的机架(第一层),要么在PS的机架(第二层)
- 梯度数据包
- 见数据结构章节
- 原因
Switch Logic(交换机逻辑)
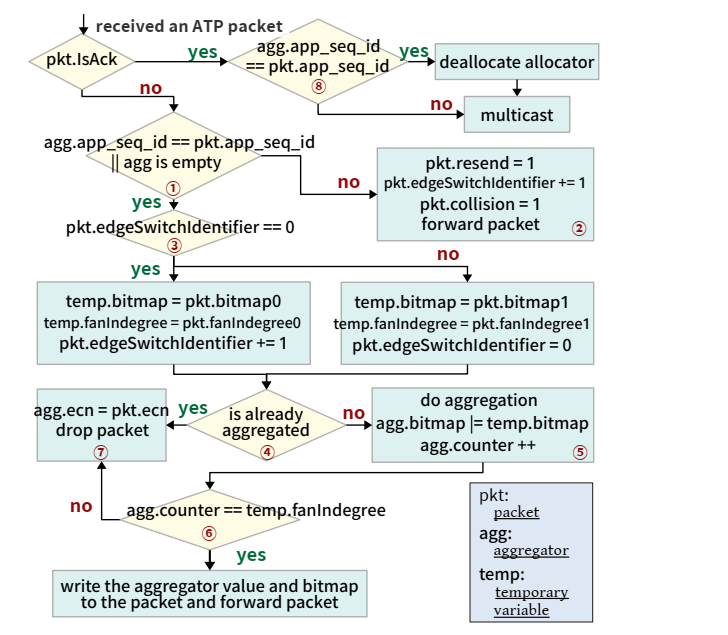
- Aggregator Allocation 聚合器分配
- 当一个梯度片段数据包到达时,交换机检查数据包的
aggregatorIndex字段中聚合器的可用性。终端主机计算aggregatorIndex为HASH( < JobID, SequenceNumber > )%numAggregators - 判断
<Job ID, Sequence Number>是非为空- 若为空,将数据包的标识符存储在聚合器中,并将梯度数据包的数据字段复制到聚合器的值字段中。交换机将聚合器中的位图字段从数据包中相应的位图字段复制
- 如果聚合器的标识符字段非空,交换机将其与数据包的标识符进行比较
- 如果它们不同,则存在哈希冲突,ATP 将梯度片段数据包向下游推送,以便在 PS 处进行处理
- 如果聚合器和数据包标识符相等,则发生梯度聚合
- 当一个梯度片段数据包到达时,交换机检查数据包的
- Gradient Aggregation 梯度聚合
- 如果梯度片段数据包有可用的聚合器,ATP 使用
edgeSwitchIdentifier从数据包中获取该交换机的扇入度和位图 - ATP
通过将数据包的位图与聚合器的位图进行比较来检查该数据包是否已被聚合
- 如果未被聚合,ATP 将数据包的梯度数据聚合(相加)到聚合器的值字段中,并将梯度数据包中的位图字段与聚合器中的位图字段进行或运算
- 如果数据包已经被聚合,ATP 将数据包中的 ECN 字段与聚合器的 ECN 字段进行或运算,并丢弃该数据包
- 比较计数器与扇入度
- 如果聚合器中的计数器小于相应的扇入度,则 ATP 会丢弃梯度片段数据包并对 ECN 进行 OR 操作
- 如果它们相等,则此交换机的聚合已完成,可以向下游推送。交换机将数据包的数据字段替换为聚合器的值字段,并将相应的位图字段替换为聚合器的位图,然后将数据包向下游发送到 PS
- ATP选择将完整的聚合结果转发给PS,而不是将它们发送回worker
- 如果梯度片段数据包有可用的聚合器,ATP 使用
- Aggregator Deallocation using Parameter Packets
使用参数包进行聚合器释放
- 当交换机从PS接收到参数包时,会将参数包多播回工作节点。参数包作为梯度片段包的确认 (ACK),并且必须遍历用于聚合的边缘交换机。当ATP交换机处理一个参数包时,交换机会检查该包索引处的聚合器是否具有匹配的标识符,如果匹配,则通过将所有字段更改为空来释放该聚合器
- Aggregator Allocation 聚合器分配
End Host Logic(终端主机逻辑)
- Worker Pushing Gradients Worker推送梯度
- ATP终端主机网络栈通过拦截DT作业的推送或拉取调用来获取梯度。它将这些梯度分成一系列306B的数据包(58B头部 + 248B梯度值)
- PS Updating Parameters PS更新参数
- ATP在PS上为每个作业分配一块内存区域,用于收集聚合梯度,形式为由序列号索引的<位图,值>数组
- 位图跟踪哪些worker的梯度片段已在值字段中聚合。PS为每个值维护一个位图,以跟踪哪些worker的值已被聚合
- 当梯度片段数据包到达时,PS将其位图与数据包的位图进行比较,以查找重叠
- 如果它们不重叠,则PS将数据包的数据聚合到其存储的值中,并从数据包的位图更新存储的位图
- 若重叠,丢弃重复项
- 完成参数片段的聚合后,PS将更新后的参数片段发送到交换机,交换机将其多播回作业中的所有worker
- 对于单个梯度片段,当最初的几个数据包到达时,聚合器可能正忙(哈希冲突),但对于后面的数据包则可用(已释放)。在这种情况下,最初的几个数据包会直接转发到PS,而剩余的数据包则在交换机处聚合
- 如果没有干预,交换机将永远不会发送聚合后的值,因为它正在等待已经发送的数据包。当工作节点接收到更高序列片段的参数数据包时,它们会检测到这种停滞的聚合,并且所有工作节点都会将停滞的片段视为丢失。每个工作节点都会重新发送带有重发位设置的停滞片段
- 为了减少聚合器冲突的频率,我们提出了一种动态哈希方案。PS检查梯度数据包的冲突位。如果冲突位被设置,PS会重新哈希以获得一个新的聚合器索引。它将这个新的聚合器索引在参数数据包中未使用的位图字段中发送给worker
- Worker Receiving Parameters 工作节点接收参数
- 网络堆栈维护一个关于梯度片段数据包序列的滑动窗口。在发送初始窗口的数据包后,工作节点将第一个未被确认的序列号记录为期望的序列号,并等待来自参数服务器(PS)的参数数据包。工作节点使用来自PS的参数数据包来滑动窗口并发送新的梯度数据包
- 当工作节点接收到一个参数数据包时,它会检查该数据包是否具有期望的数据包序列号
- 如果该参数数据包已被接收,则会被忽略
- 如果它具有期望的序列号,则工作节点会增加期望的序列号,并调用拥塞控制算法来更新当前窗口
- 如果正在传输的数据包数量小于拥塞窗口,ATP将发送剩余窗口(拥塞窗口大小 - 正在传输的数据包数量)的梯度片段数据包
- 如果参数的序列号高于预期,ATP可能会认为期望的梯度片段丢失,从而触发丢失恢复
- Worker Pushing Gradients Worker推送梯度
Reliability and Congestion Control(可靠性和拥塞控制)
- Reliability 可靠性
- 当worker接收到三个连续的、序列号不是期望序列号的参数包时,它会检测到具有期望序列号的梯度片段丢失
- ATP worker会重传丢失的片段包,并设置重发位;这向交换机表明交换机中可能存在部分聚合状态
- 在第一级,当重传数据包到达时,交换机检查是否存在匹配的聚合器
- 如果存在,并且聚合器位图未指示重传数据包的片段已被聚合,则交换机将数据包中的值聚合到聚合器中,将数据包中的位图合并到聚合器的位图中,将结果(可能是部分的)向下游转发,并释放聚合器
- 第二层交换机丢弃其聚合状态,并将任何重发的包(包括来自第一层的部分聚合)转发到PS,在那里最终完成聚合
- 在每个参数包上,交换机都会检查由参数包索引指定的寄存器的超时值。即使其作业ID和序列号与参数包不匹配,如果时间戳早于配置的值,交换机也会释放聚合器
- Congestion Control 拥塞控制
- 在多租户网络中,多个ATP作业和其他应用程序共享网络。它们争夺各种资源,包括网络带宽、接收器CPU和交换机缓冲区。在ATP中,多个作业还会争夺交换机上的聚合器
- 交换机中聚合器的高度争用可能导致聚合器无法聚合所有流量。这会导致流量增加,从而触发交换机中的队列长度累积以及由于交换机缓冲区溢出而导致的丢包
- 启用交换机中的ECN标记,并使用ECN和(罕见的)数据包丢失作为拥塞信号。为了确保ECN标记在聚合期间不丢失,ATP将分片数据包中的ECN位合并到聚合器中的ECN位,该ECN位稍后在聚合完成后转发到PS。然后,此ECN位被复制到参数数据包,并最终到达所有worker
- 每个ATP工作进程应用加性增量乘性减量(AIMD)来调整其窗口大小,以响应拥塞信号
- 对于每个收到的参数包,ATP将窗口大小增加一个MTU(1500字节或5个数据包),直到达到一个阈值。高于慢启动阈值时,ATP每个窗口将窗口大小增加一个MTU
- 当一个工作进程通过参数ACK上的ECN标记或三个乱序ACK检测到拥塞时,它会将窗口大小减半,并将慢启动阈值更新为更新后的窗口大小
- Reliability 可靠性
Dealing with Floating Point(浮点数处理)
- ATP通过将浮点数乘以一个比例因子 (108) 并四舍五入到最接近的整数,将每个worker处的梯度值从32位浮点表示转换为32位整数表示
- 交换机聚合这些32位整数,PS通过除以比例因子将聚合值转换回32位浮点数
- 所有梯度数据包都以在网络交换机上进行聚合为目的发送。如果一个梯度数据包在交换机中的聚合器上触发溢出,我们利用交换机的一个特性(饱和)将聚合器的值设置为用32位整数表示的最大值或最小值
- 果聚合器的值已饱和,则任何进一步发送到该聚合器的梯度数据包仅更新方向,并且该值保持饱和。当聚合完成时,即fanInDegree值等于worker的数量时,饱和的聚合器值被写入梯度数据包并发送到PS。如果PS发现聚合器的值已饱和,它会从所有worker请求原始的浮点格式的梯度值。这会触发重传,并且所有worker都将包含浮点梯度值的包直接发送到PS,PS最终执行聚合
4. Implementation 实现
- Programmable Switch 可编程交换机
- 该交换机实现具有用于梯度聚合的处理逻辑以及用于分配、释放和管理聚合器的控制逻辑
- 必须在有限的时间预算内解析整个数据包,并在有限的交换机流水线阶段中进行处理
- 聚合
- ATP通过对每个数据包在交换机上进行两次处理(称为两遍处理)来增加此限制,这是重提交和循环功能的混合使用
- 控制逻辑
- 负责检查聚合器是否可用,处理协议标志,以及更新聚合状态
- 为了在对寄存器的一次性访问限制内工作,ATP应用各种技术来处理复杂操作。考虑位图检查过程,这涉及到读取聚合器中的位图,然后对梯度值和位图值进行算术运算;最后,写入聚合器中的位图
- ATP中解决单个数据包的一次性访问限制的另一种方法是使用两个数据包
- End-Host Networking Stack 终端主机网络堆栈
- 将 ATP 实现为 BytePS插件,该插件集成在 PyTorch、TensorFlow和 MXNet中
- BytePS 允许在不修改应用程序的情况下使用 ATP。ATP 在 worker 与 ATP PS 通信时,拦截 worker 上的 Push 和 Pull 函数调用
- Small Packet Optimizations 小数据包优化
- TSO通过将数据包分包卸载到网卡来加速数据包发送,并通过大型DMA传输来提高PCIe带宽
- MP-QP使用指定多个连续数据包缓冲区的缓冲区描述符,并将网卡内存占用减少至少512倍
- ATP使用多线程来加速数据包处理
- Baseline Implementation 基线实现
- 实现了一个SwitchML的原型,它使用交换机作为PS,并提供基于超时的丢包恢复机制
- 在终端主机上将TSO和MP-QP特性应用于SwitchML实现,以改善小包操作,但不在交换机上应用两阶段优化,以与SwitchML的公共版本保持一致
5. Evaluation 评估
- 实验装置
- 集群设置
- 8台机器配备了一块NVIDIA GeForce RTX 2080Ti GPU,NVIDIA驱动版本为430.34,CUDA版本为10.0
- 所有机器均配备56核Intel(R) Xeon(R) Gold 5120T CPU @ 2.20GHz,192GB RAM,操作系统为Ubuntu 18.04,Linux内核版本为4.15.0-20。每台主机都配备一个Mellanox ConnectX-5双端口100G NIC,使用Mellanox驱动OFED 4.7-1.0.0.1。所有主机通过一个具有Barefoot Tofino芯片的32x100Gbps可编程交换机连接
- Baseline 基线
- BytePS
- SwitchML
- 具有RoCE的Horovod
- 具有TCP的Horovod
- Workloads 工作负载
- DT 作业有 8 个 worker。对于大多数实验使用 VGG16(模型大小 528MB)和 ResNet50(模型大小 98MB),分别作为网络密集型和计算密集型工作负载的代表
- 还运行一个聚合微基准测试,其中每个 worker 重复传输 4MB 张量(BytePS 支持的最大大小),这些张量在网络 (ATP) 中或在 PS(s) (BytePS) 中聚合,然后发送回 worker。与真实作业相比,此微基准测试具有大小相等的张量,并且始终有数据要发送,没有“关闭”阶段
- Metrics 指标
- DT作业的训练吞吐量
- 达到目标准确率的时间
- 微基准测试的聚合吞吐量
- 集群设置
- 单任务性能
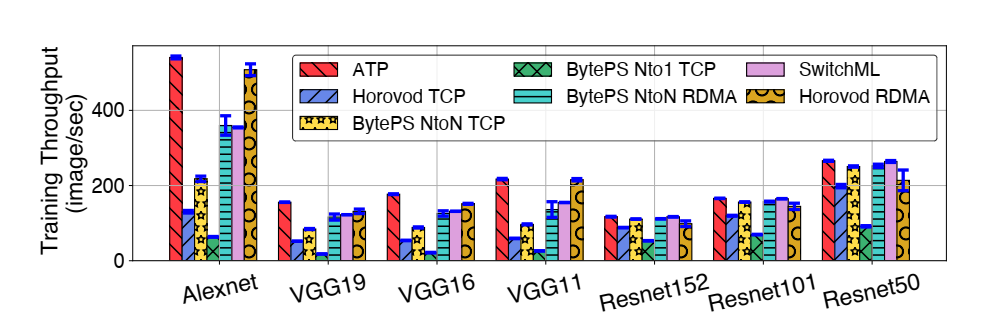
- ATP训练性能
- 对于所有作业,ATP均实现了最佳性能,在网络密集型工作负载(VGG)上,性能提升比在计算密集型工作负载(ResNet)上更大
- 机架间聚合
- ATP在发送到PS之前,在交换机SW2处聚合来自w5和w4的单个数据包以及来自SW0和SW1的部分聚合;这消除了到PS的$\frac{2}{3}$的流量
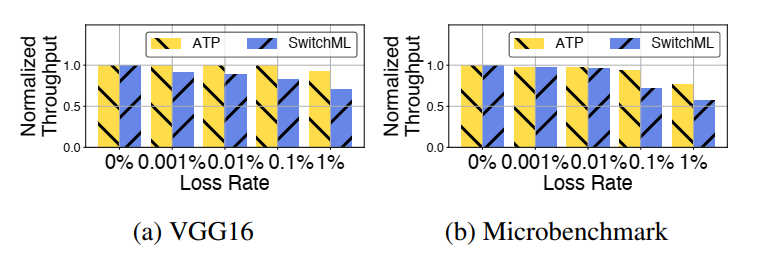
- 丢包恢复开销
- 当丢包率增加时,ATP的性能会优雅地降低,且降低程度小于SwitchML。这是因为ATP采用乱序ACK作为丢包信号,这使得ATP能够比SwitchML更快地检测和响应丢包
- ATP训练性能
- ATP Time-to-Accuracy (TTA)ATP 准确率时间
- 单任务TTA
- 对于所有模型,ATP花费相同数量的epoch来达到与BytePS NtoN RDMA相同的top-5准确率
- 对于VGG16,一种网络密集型工作负载,ATP优于BytePS
- ATP没有加速ResNet50的训练,因为它是一种计算密集型工作负载
- 多任务TTA
- 与单作业 TTA 性能类似,ATP 优于 BytePS 和 Horovod
- ATP不会影响训练质量,并且由于网络内聚合提供的加速作用,它能够在比其他方法更短的时间内达到基线训练精度
- 单任务TTA
- 多重作业
- 动态 vs. 静态共享
- 在 100% 的情况下,动态方法与静态方法的性能相似
- 随着可用聚合器数量的减少,动态方法的吞吐量下降幅度小于静态方法
- ATP哈希方案的有效性
- ATP的基于哈希的方案与基准静态方案相匹配,并且大大优于基于线性的方案
- 动态哈希函数可以有效地将聚合器分配给每个作业
- 动态 vs. 静态共享
- 拥塞控制的有效性
- With non-ATP traffic 非ATP流量
- 有ATP的VGG16作业能够达到峰值吞吐量(因为需求小于公平份额),并且吞吐量之和接近该工作节点上行链路的线路速率。这表明,在这种设置下,ATP的CC能够与具有最大-最小公平分配的非ATP后台流量共存
- ATP能够接近瓶颈链路(来自该工作节点的上行链路)的公平份额,并且两种流量类型的吞吐量之和接近链路速率。这展示了近乎公平的链路带宽共享
- With other ATP traffic ATP流量
- ATP的拥塞控制能够有效地维持高吞吐量,并且能够有效地避免丢包
- With non-ATP traffic 非ATP流量
6. Other Related Work 其他相关工作
- Speedup Network Transmission 加速网络传输
- 更智能的网络调度
- 通过细粒度张量传输调度(按层而不是整个梯度或参数)来增加GPU/CPU计算和网络传输之间的重叠
- 通过流水线结合模型并行和数据并行
- 使用异步IO
- 减少网络流量
- 用大批量大小来降低通信频率
- 使用量化或减少SGD中的冗余来减少网络传输的字节数
- 优化本地-全局聚合的混合,以适应运行时的网络变化
- 更智能的网络调度
- In-network Aggregation 网络内聚合
- 已在无线网络中、在大数据系统和使用终端主机的分布式训练系统中、专用主机、高性能中间盒或覆盖网络中进行了探索
- DAIET提出了一个简单的网络内聚合的概念验证设计,但没有测试平台原型
- ShArP在Mellanox Infiniband专用交换机的支持下,构建了一个覆盖缩减树来聚合通过它的数据,但它直到交换机接收到所有数据后才应用聚合
7. Conclusion 结论
- 成功构建了一个网络内聚合服务ATP,以加速多租户多机架网络中的DT作业
- 对于单个作业,ATP的性能优于现有系统高达8.7X,甚至略优于当前最先进的基于RDMA的环状all-reduce
- 在多租户场景中,使用ATP的尽力而为的网络内聚合能够实现高效的交换机资源利用,并且在交换机资源竞争激烈时,在训练时间方面优于当前最先进的静态分配技术高达38%
ATP:多租户学习中的网络内聚合
http://example.com/2025/07/16/ATP:多租户学习中的网络内聚合/